
Table of Contents
現代の企業は、膨大かつ増え続ける規制や企業責任に関する要請に直面しています。この急速に変化する環境において、リスク管理、調達、コンプライアンスなどの各部門は、対応に苦慮しており、アラートに疲弊するという現実的な課題によって業務遂行の効率性が低下しています。
コンプライアンス違反は、罰金、風評リスク、投資家や株主の信頼への悪影響など、大きな代償を伴う可能性があるため、サードパーティリスクの管理部門は、当然ながら慎重な対応を取る傾向にあります。しかしながら、企業をリスクから守るこれらの部門の使命は、リスクのない企業との取引を可能にする必要性とバランスを取っています。
「ホワイトリスト」は、アラートを抑制し、サードパーティリスクの管理部門の時間を節約し、デューデリジェンスの効率を最大化するために、先手を打つ対応として導入できる有用な戦術です。しかしながら、多くのこのような部門は、ホワイトリストに登録する意思決定を確信を持って行うために必要なデータとコンテキストを欠いているのが実情です。
このeBookでは、ホワイトリスト作成の実践に関するインサイトを提供し、明確なホワイトリスト作成の意思決定を支援するためのエンティティの曖昧性を解消する手法の活用も紹介します。また、注目しているエンティティに関する包括的なコンテキストを提供するSayariデータを活用して、リスク管理部門がホワイトリスト作成プログラムをどのように実現しているかについても詳しく説明します。
ホワイトリストとは何か?
ホワイトリスト化とは、特定のサプライヤー、顧客、パートナー、その他の第三者が、企業とのビジネス上の取引を行うことを承認するプロセスを指します。
ホワイトリスト化を進める実務上のメリットは、誤検知の削減によってデューデリジェンスの効率が向上することです。多くのコンプライアンス部門は、既にキャパシティの限界、あるいはキャパシティを超えている状況にあります。ホワイトリスト化は、審査済みのエンティティを将来の取引ができるように承認を行うことで、デューデリジェンスプロセスの手間を軽減し、リスク管理にかかるリソースを削減することを可能にします。これは結果的に、コンプライアンス部門の業務の円滑化を図り、コンプライアンスの審査によって取引が遅延する可能性のある第三者との摩擦を軽減することにつながります。
ホワイトリストは、一般的に、1) 既知のリスクが無いエンティティを承認する場合、または2) リスクが企業に直接影響を与えない、もしくはリスクが許容範囲内にあるエンティティを承認する場合に用いられます。後者については、個々の企業のリスク許容度とポリシーに依存するため、この記事では1)の既知のリスクが無いエンティティのホワイトリスト化に焦点を当て、お伝えしていきます。
既知のリスクが無いエンティティをホワイトリストに登録する最初のステップは、エンティティの曖昧さをなくすため、異なる第三者を明確に区別することです。これは、サプライヤー、顧客、ベンダー、販売業者など、すべての第三者に対する正確なリスク評価において不可欠なプロセスです。通常、データソースを複数活用する場合、それぞれのデータソースで命名規則が多様かつ不統一であるため、実在する同じ企業を参照するプロファイルを正しく識別し、統合することが不可欠です。しかしながら、正確で多様な情報が十分に含まれたエンティティのプロファイルを入手することは困難な場合があります。
効果的なホワイトリスト作成における障壁
コンプライアンス部門の大多数は、デューデリジェンスを目的としたスクリーニングのために、1社以上のサードパーティデータプロバイダーに依存しています。しかし、これらのプロバイダーがデータをどこから入手しているかによって、情報のギャップやその他の障壁が生じ、ホワイトリストに登録するプログラムが機能しない可能性があります。
規制当局や執行機関がリストベースの指定から、ナラティブと呼ばれるような領域、つまりリストに明示されていなくても、その特徴や条件に当てはまれば規制対象とすることや、または同類系の内容を一様に禁止する方針へ移行する傾向にあることも、これらのデータにおける課題の一因となっています。たとえば、ウイグル強制労働防止法(UFLPA)は、中国政府による新疆ウイグル自治区のウイグル族やその他の少数民族に対する強制労働への対応として、新疆産の材料を全部または一部使用した製品の米国への輸入を禁止しています。米国税関・国境警備局(CBP)は、米国への輸出が明示的に禁止されている事業体を特定するUFLPAエンティティリストを公開していますが、貿易または株式などの所有権を通じて新疆ウイグル自治区に関係する企業は、このような法律の下でリスクを負うことになります。この規制やその他のナラティブ規制に準拠するために、企業はすべての第三者に関する包括的な情報を入手し、効果的なリスク判断を行う必要があります。
このような背景の結果として、ホワイトリスト化における一般的なデータ障壁には次のようなものがあります。
- ウォッチリストの情報が不十分
ホワイトリスト化の決定は、多くの場合において、少なくとも部分的にはウォッチリストのデータに依存しますが、その情報は名前と住所に限定されている場合もあります。納税者番号などの固有の識別情報がなければ、確信を持って曖昧さを解消することは困難を伴います。 - 過度なリスク検出
多くのサードパーティスクリーニングソリューションは、リスクの高いエンティティをカタログ化し、企業がスクリーニング対象となる包括的なウォッチリストデータベースを作成することに重点を置いています。しかし、ターゲットを規制対象ではないエンティティとして特定することは、最初のステップに過ぎません。ホワイトリスト化の決定における信頼性を最大限に高めるには、対象となるエンティティが確実にリスクがないエンティティのプロファイルと一致し、その決定が裏付けられることが最も効果的です。ウオッチリストに掲載されているエンティティとウォッチリストに関連するエンティティが識別されていないデータセットではこのユースケースに役立ちません。 - ナラティブデータ不足
広範な類型に適用されるナラティブまたは暗黙的な制裁や規制には、包括的なスクリーニングリストが含まれていません。このような場合、コンプライアンス部門は、対象となるエンティティの取引活動、企業間の関係、行動など、追加のコンテキスト情報を入手し、効果的にホワイトリストまたはブラックリストに登録する必要があります。 - 名寄せ技術不足
多くの企業では、リスクスクリーニングでフラグが付けられたエンティティに対して、手動で曖昧性を解消し、調査する作業をアナリストに委ねています。曖昧性解消に使用するエンティティデータが十分に整理されていない場合、この作業は持続不可能となり、曖昧性解消に膨大な時間がかかることになります。曖昧性を解消するロジックを用いて多くのエンティティを自動的に解決するソリューションは、コンプライアンスに従事する人々や調達に従事する人々が迅速に焦点を絞り込み、より効率的な業務を遂行することに貢献します。
インテルのグローバル制裁担当ディレクター兼KYC(Know Your Customer)の責任者であるジェイソン・ローデス氏は、ホワイトリスト化に伴うこうした課題は業界を問わず共通していると述べています。「評価対象の企業が調達先であろうと、販売先であろうと、リスク管理のために同じプロセスを実行することになります。」制裁関連の業務を通じて複数のホワイトリスト化プログラムを構築してきたローズ氏にとって、ホワイトリスト化とは「コンプライアンス部門が誤報に悩まされることがないよう、リスクを積極的に軽減すること」であると述べています。
適切なツールがあれば、コンプライアンスに携わる部門は次のホワイトリスト化するための手法を一つないし複数取り入れることで、より効率的にリスクを軽減していくことが実現できるのです。
ホワイトリストを作成する手法
リスクスクリーニングにおいて、非リスクエンティティがフラグ付けされる理由はいくつかあります。よくある理由の一つは、ウォッチリストに登録されているエンティティと、固有でない識別情報(名前や住所など)が共通していることです。もう一つの理由は、そのエンティティの名前がウォッチリストに登録されているエンティティの名前と類似していることです。これらのアラートは「曖昧なマッチング」による結果であり、入力ミスや誤記によって企業がリスクにさらされないように、名前が完全一致ではない場合もフラグを付けます。エンティティ名の英語翻訳がウォッチリストに登録されているエンティティ名と類似している場合もありますが、翻訳されていない名前の場合は全く類似していないケースもあります。
いずれにしても、コンプライアンスに関わるアナリストは、デューデリジェンスを実行する前に、まずフラグが付けられたエンティティの曖昧さを解消する必要があります。
曖昧さの解消と単一エンティティのホワイトリスト化
単一のエンティティをホワイトリストに登録する前段階として、調査員には曖昧さを解消するために取れるアプローチが 4つあります。
- 固有の識別情報
エンティティの曖昧性を解消する最も効率的な方法は、固有の識別情報を使用することです。固有の識別情報とは、システム内の単一のエンティティに関連付けられた数値または英数字の文字列です。複数のドキュメントで固有の ID が参照されている場合、それらは同じエンティティを指していると確信できます。ただし、識別子を一方的に曖昧性を解消するために使用する前に、その識別情報が固有のものであることを確認する必要があります。たとえば、識別情報は特定の期間内では固有であっても、すべての期間にわたって固有であるとは限りません。これは、会社の閉鎖や人の死亡などの事象によって、一部の固有の識別情報が再利用されるためです。この現象は、文書の更新が頻繁にある米国のパスポート番号に見られます。 - 固有でない識別情報の組み合わせ
固有の識別情報がない場合、調査員が次に用いることができる曖昧性の解消手法は、固有でない識別情報を組み合わせることです。電話番号や生年月日は単独ではあまり役に立ちませんが、住所や国籍などの他の固有でない識別情報と組み合わせることで、より詳細にその像を浮かび上がらせることができます。 - 関係の共起
調査員は、有用な識別情報がないものの曖昧性を解消しなければならない場合があります。そのような場合、調査員は識別情報を超えて、エンティティ間の関係性、つまり「関係の共起」に関する情報を用いて曖昧性を解消する必要があります。
例えば、Yu Hongpingという名前の中国人2人がおり、それぞれ異なる中国企業を率いていると仮定しましょう。この2つの企業はどちらもファッション業界に属し、香港に共通の親会社があることが分かれば、2人のYu Hongpingは同一人物である可能性が高いと推測できます。 - 名前の出現頻度とその他の文脈的要素
名前の出現頻度とその他の文脈的要素は、それ自体だけでは信頼性が低い傾向にありますが、上記の3つの手法のいずれかを用いて既に行った評価を確認したり、さらに裏付けたりする時に役立ちます。例えば、特定の管轄区域において、対象者の名前がどの程度一般的であるかを考慮し、名前の一般性が低いほど、その同じ名前が2回出現した場合、その人物が同一人物を指している可能性が高くなります。有権者名簿は、人口における名前の出現頻度を評価するための優れたツールであり、一部の国で公開されています。
これらのアプローチを1つ以上使用することで、企業内部のコンプライアンス部門は、潜在的にリスクがあるとフラグ付けされたエンティティが実際に管理対象エンティティであるか、それとも一部の識別情報に基づいて管理対象エンティティのように見えるだけであるかを判断できます。これにより、明確になった個々のエンティティを安全にホワイトリストに登録することができ、将来のリスクアラートやデューデリジェンスの繰り返しを回避できます。
複数の既知のエンティティのホワイトリスト化
複数の既知のエンティティを一度にホワイトリストに登録することができれば、頻繁に発生するアラートによる疲弊を軽減することができます。
例えば、リスクのない取引相手であるJohn Doeという人物がいるとします。悪名高い制裁対象者であるJohn Doe, Jr.と混同される可能性がある場合、John Doeをホワイトリストに登録します。John Doeの曖昧性を排除してホワイトリストに登録し、社内データからJon R. Doe、John Doen、Jonathan Doeなど、類似の名前を持つ審査済みの人物を検索し、それらも積極的にホワイトリストに登録することで、将来的に必要のないアラートの誘発を防げるのです。
サードパーティエンティティリストのホワイトリスト化
制裁対象企業と誤認される可能性のある、リスクのない企業のサードパーティリストにアクセスできる場合は、その企業をホワイトリストに登録しておくことで、万が一、制裁対象企業が関与した場合に、偽装工作を未然に防ぐことができます。この手法は多くの企業が必要とするよりもさらに積極的な方法ですが、特にサードパーティを迅速にスクリーニングする必要がある大企業は、これを競争上の優位性を確保するために活用しています。例えば、金融機関にとって、迅速なスクリーニングは差別化要因となり得ます。
上記の John Doe の例を基に、サードパーティのデータプロバイダーを使用して、John Doe, Jr. に似た名前を持つリスクのないエンティティのリストを作成し、これらをホワイトリストに登録して、今後この名前に遭遇した場合に、デューデリジェンス担当部門に不要な作業が発生しないようにすることができます。
ホワイトリストに登録されたエンティティの継続的な監視
ホワイトリストはブラックリストと同様に、リスクステータスの変化を確実に把握するために継続的に監視する必要があります。今日安全な企業が明日にはウォッチリストに追加される可能性があり、また、最近の行動、企業間の関係、取引活動に基づいたナラティブな方法の規制によって監視対象とされる可能性もあります。リスクステータスに関わらず、すべてのサードパーティを監視する必要があると言えます。自動スクリーニングソリューションは、ホワイトリストに登録された企業がウォッチリストに追加された場合、またはリスクがあると判断された場合にアラートを表示することで、企業内のコンプライアンス部門の業務支援をします。

Sayariによってホワイトリスト化をかなり容易にすることが可能です。Sayari導入前は、制限対象者を区別する方法が限られており、正当な第三者との取引を誤って停止しないように対応することが困難でした。Sayariは広範なエンティティにわたるデータを収集・処理・可視化することで、ホワイトリストへの登録をサポートしてくれます。
Sayariによるホワイトリスト
企業が効果的にホワイトリストを作成するには、深く幅広く、かつ適切に分類されたエンティティデータが必要です。Sayariは、ウォッチリストに登録されたエンティティだけではなく、モデルに含まれる29億のエンティティすべてについて包括的なプロファイルとネットワークコンテキストを提供することで、これらの要件を満たしています。
「Sayariを使う前は、制限対象の当事者を区別する方法が限られており、問題の無い第三者との取引を阻止しないようにするのが困難でした」とローデス氏は言います。Sayariは、幅広いエンティティからデータを収集、処理、可視化することで、ホワイトリスト化を容易にしています。
Sayari のソリューションは、信頼性の高いホワイトリストプログラムを実現するためにさまざまな機能を提供しています。
- 高精度の名寄せで誤検知を最小限に抑える
信頼性の高いホワイトリストの作成は、信頼できる名寄せから始まります。Sayari 独自の名寄せ手法は、アイデンティティ解決とPossibly Same As (PSA)解決という 2 つのアプローチにより誤検知を軽減します。アイデンティティ解決は、実在する同じ企業を参照する確実な情報を収集し、それらを一つのエンティティに集約します。通常、これらの厳格な解決方法には、強力もしくは固有な識別情報の一致 (納税者番号など)、または弱い識別情報の組み合わせ (名前と住所、名前と生年月日など) が用いられます。
これに対し、PSA による解決方法は、実在する企業を参照する可能性が高いエンティティをグループに集約します。この名寄せに対する保守的なアプローチにより、名寄せ漏れによって生じる誤検知を軽減します。PSA グループは構成要素となっているエンティティ単位でキュレーション可能なため、調査員が独自のデータに基づいて結果を採用または拒否する余地を残します。
Sayari は誤検知を一切許容しないことを目指しており、過剰な名寄せを避けることで、不正確なホワイトリストが確定することを防止しています。 - 包括的なエンティティプロファイルでウォッチリストデータを補足
詳細情報が豊富に含まれるエンティティプロファイルは、確実なホワイトリスト作成を可能にするためにこれまで述べたことと同様に重要なものです。各エンティティについて、Sayari は住所、生年月日、事業内容、財務、取引データ、リスク要因、アドバースメディアにおける言及などの属性を提供しています。また、関連会社、輸出入貨物、資産などの情報をいずれも信頼できる情報ソースの該当箇所を引用しエンティティ情報に付加しています。
ウォッチリストは詳細情報が不十分な傾向があるため、エンティティを明確に特定することが困難です。例えば、Beijing Androtech という会社が、ウォッチリストに登録されている軍事エンドユーザー (MEU) である Beijing Ander Tech と曖昧一致のフラグが立てられていると想像してください。BIS (米国商務省産業安全保障局)のエンティティリストには、Ander Tech の名前と住所しか記載されていません。つまり、たとえ Androtech について十分な情報 (固有の識別情報や北京の別の住所など) があったとしても、Androtech が Andertech と何らかの関連がないと確信を持って証明することはできないのです。

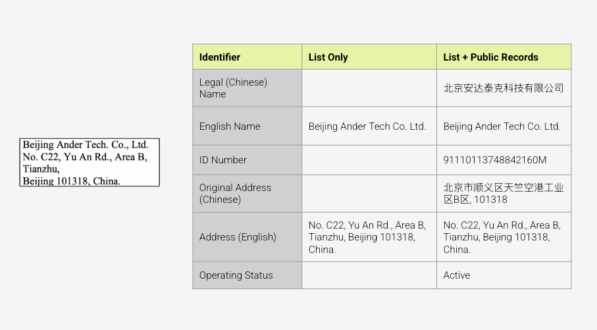
- ネットワーク化されたデータにより、ナラティブなリスク評価が可能
昨今、コンプライアンス部門は、エンドユーザーリスクの可能性を特定するために、企業の所有と支配を精査する必要があります。株主や子会社などの公開記録に含まれる追加情報は、信頼性の高い意思決定とホワイトリストを作成することに有用です。例えば、取引上で上流および下流の企業関係を調査し、取引相手が既知の高リスクエンドユーザーと直接的または間接的なつながりを持っているかどうかを判断することは、輸出規制品目が規制対象者へ流用される可能性を軽減する効果的な方法となり得ます。
Sayariのネットワーク分析および可視化機能により、サードパーティリスクを管理する部門は、企業を個別に検討する必要はなく、関連する個人、企業、輸出、資産の全体像に基づいて評価を行うことができます。Sayariは、異なるデータソース間の点と点を自動的に結び付けます。これは、所有と支配の関係をマッピングする際に特に役立ちます。隠れていた関係性が自動的に明らかになり、調査員の理解を深め、場合によっては変革をもたらすこともあります。Sayariが保有する過去の記録は、潜在的な隠蔽工作が存在するような場合でも、コンプライアンス部門が企業の過去の関係性や行動を評価できるように支援することが可能です。
上記の例に戻ると、Sayariのネットワーク化されたデータにより、Ander TechはBISの軍事エンドユーザー(MEU)リストへの掲載だけでなく、サプライヤーネットワークに新疆ウイグル自治区を拠点とする企業が含まれているといったナラティブ情報によるリスクについてもフラグ付けされます。このような包括的にリスクフラグを付ける機能によって、ホワイトリスト登録前の徹底的なスクリーニングを確実に実施することが可能なのです。 - 広範なデータセットがターゲットの発見を支援
Sayari のデータは、世界中の 250 以上の管轄区域にわたる 7 億社以上の企業と 7 億 2,500 万人以上の個人をカバーする 80 億件以上のレコードで構成されています。Sayari のリスク指標はエンティティリストにとどまらず、高リスクのナラティブな情報の類型も含んでいますが、Sayari のデータセット内のエンティティのうち、リスクのフラグが付けられているのは 2% 未満であり、ネットワークコンテキストの重要性が強調されています。
Sayariは、できるだけ幅広いエンティティのデータを提供することで、コンプライアンス部門が、フラグが付けられた当事者 (上記の Androtech など) を Sayari 内の対応するプロファイルと確実に一致させることができる可能性を高めています。このような一致を確立することで、そのエンティティに対するさらなるデューデリジェンスが可能になり、当該部門がリスク判断の根拠を裏付けることができるのです。
まとめ
規制環境は今後ますます複雑化すると予想されるため、サードパーティのリスクを管理する部門は、可能な限り効率化を図り、過剰なコンプライアンス業務を最小限に抑えることを目指しています。ホワイトリスト化はこうした目的を達成するための手段であり、特定のリストに名前が載っていなくても、その特徴や条件に当てはまれば規制対象になるような貿易規制や、それがもたらす規模の問題に対応するデューデリジェンスプログラムにとって不可欠な要素となっています。Sayariは、膨大なデータモデルと詳細なエンティティプロファイルを備えており、ホワイトリスト作成プロセスにおいて重要な役割を果たします。Sayariは、コンプライアンス部門がリスクが存在しないことを確信を持って主張し、デューデリジェンスの取り組みによる業務の混乱を最小限に抑えることに役立つのです。