
Table of Contents
Organizations today face a large and growing list of regulations and corporate responsibility requirements. In this fast-paced environment, risk management, procurement, and compliance teams struggle to keep pace. Alert fatigue is a real challenge that drains efficiency.
Because the price of non-compliance can be steep in terms of penalties, reputation loss, and impact to investor and shareholder confidence, teams managing third party risk rightfully err on the side of caution. However, teams must balance this protection with the need to do business with legitimate partners.
Whitelisting is a proactive tactic that can limit alerts, return time to third-party risk management teams, and maximize due diligence efficiency. Unfortunately, many organizations lack the data and context required to make these whitelisting decisions confidently.
This ebook offers insight into whitelisting practices, including the use of entity disambiguation to support clear-eyed whitelisting decisions. It also details how organizations are using Sayari data, which offers comprehensive context on entities of interest, to enable their whitelisting programs.
What is whitelisting?
Whitelisting is the process of approving specific suppliers, customers, partners, and other third parties to participate in business operations with an organization.
The primary benefit is efficiency: it reduces false positives. Most compliance teams are already at or over capacity without the burden of repeat alerts. By clearing vetted entities for future engagement, whitelisting helps de-noise the due diligence process and conserve risk management resources. The result is smoother operations and less friction for your partners whose transactions might otherwise be delayed by compliance screening.
Whitelisting is commonly employed to either: 1) approve an entity with no known risk or, 2) approve an entity whose risk does not directly impact the organization or is within acceptable limits. Because the latter use case hinges on individual organizations’ risk appetites and policies, this discussion focuses on whitelisting entities with no known risk.
The first step is entity disambiguation, or the process of clarifying or differentiating between different third-party actors to avoid confusion or ambiguity. This is crucial for accurate risk assessment of all third parties, including suppliers, customers, vendors, distributors, and others. Because naming conventions vary across data sources, you must identify and merge profiles that refer to the same real-world entity. Sufficiently comprehensive entity profiles can, however, be difficult to procure.
Barriers to effective whitelisting
Most compliance teams rely on one or more third-party data providers for due diligence screening. Still, depending on where these providers source their data, there can be information gaps and other barriers to whitelisting programs.
A trend among regulatory and enforcement agencies away from list-based designations toward “narrative” or typology-based prohibitions has contributed to these data challenges. For example, the Uyghur Forced Labor Prevention Act (UFLPA) responds to the Chinese government’s use of forced labor against Uyghurs and other ethnic minorities in the Xinjiang region by banning any product made either wholly or in part with materials from Xinjiang from entering the U.S. While U.S. Customs and Border Protection (CBP) maintains a UFLPA Entity List identifying entities explicitly prohibited from exporting to the U.S., any company linked to Xinjiang province — whether through trade or ownership — carries risk under the law. To comply, companies must obtain comprehensive contextual information on all third parties in order to make effective risk decisions.
Common data barriers to whitelisting include:
- Insufficient watchlist details. Whitelisting decisions often depend — at least in part — on watchlist data, which can sometimes be limited to a name and address. Without unique identifiers, such as corporate tax ids, it can be hard to confidently disambiguate.
- Overemphasis on risky entities. Many third-party screening solutions focus on cataloging risky entities to create a comprehensive database of watchlists for companies to screen against. Identifying targets as non-restricted, however, is only the first step. Confident whitelisting decisions are best supported by a positive match between the entity of interest and a complete, non-risky entity profile. Datasets almost entirely composed of watchlisted and watchlist-adjacent entities cannot support this use case.
- Insufficient narrative data. Narrative or implicit sanctions and regulations that apply to a broad typological group do not include a comprehensive screening list. In these cases, organizations need additional context — like trade activity, corporate relationships, and behavior — to make a decision.
- Poor entity resolution. Many organizations assign analysts the task of manually disambiguating and investigating entities flagged during risk screening. This becomes unsustainable if the entity data they’re using to disambiguate is not sufficiently resolved; disambiguation takes too long. Solutions that use disambiguation logic to automatically resolve entities at scale help compliance and procurement teams move faster.
Jason Rhoades, Global Sanctions Director and head of KYC at Intel, says these whitelisting challenges are common across industries. “Whether the entity you’re assessing is making a payment or receiving a shipment, you’re undertaking the same process to manage risk.” For Rhoades, who has built several whitelisting programs over the course of his sanctions engagements, whitelisting is about “proactively mitigating risk to keep teams from being inundated with false alerts.”
With adequate tooling, organizations can effect more efficient risk mitigation by employing one or more of the following whitelisting techniques.
Whitelisting approaches
There are a number of ways a non-risky entity might be flagged during risk screening. One common reason is that they share one or more non-unique identifiers (such as a name or address) with a watchlisted entity. Another is that their name is similar to that of a watchlisted entity. These alerts are the result of “fuzzy matching” protocols, which flag non-exact name matches to ensure that the organization isn’t exposed to risk on account of a typo or clerical error. Sometimes the English translation of an entity name is similar to that of a watchlisted entity, even though the untranslated names bear no resemblance to one another.
Compliance analysts must disambiguate these flagged entities before performing due diligence.
Basic disambiguation and single-entity whitelisting
Investigators have four primary approaches to disambiguation as a precursor to whitelisting a single entity:
- Unique identifiers
The most efficient way to disambiguate entities is to use a unique identifier. A unique identifier is a numeric or alphanumeric string that is associated with a single entity within a system. If you see a unique ID referenced in multiple documents, you can be confident that they refer to the same real-world entity. However, you must confirm that an identifier is unique before using it to unilaterally disambiguate. An identifier can, for example, be unique within a specific time period but not across all time periods. This is because some unique identifiers are recycled, such as after a company’s closure or a person’s death. We see this with U.S. passport numbers, which often change when the document is renewed.
- Combinations of non-unique identifiers
In the absence of unique identifiers, an investigator’s next-best disambiguation technique is to combine non-unique identifiers. A telephone number or date of birth might not be much help on its own but can begin to create a more detailed picture when layered with other non-unique identifiers, such as physical address or citizenship.
- Relationship co-occurrence
Sometimes, investigators must disambiguate without any useful identifiers, unique or otherwise. Investigators must then go beyond identifiers to disambiguate using information about relationships between entities, or “relationship co-occurrence.”
For example, let’s imagine that we have two Chinese individuals by the name of Yu Hongping, each of whom directs a different Chinese company. When we learn that these two companies are both in the fashion industry and share a parent company out of Hong Kong, we can infer that the two Yu Hongpings are likely the same individual.
- Name frequency and other contextual factors
Using name frequency and other contextual factors tends to be less authoritative on its own but can help confirm or further support an assessment you’ve already made using one of the three techniques above. For example, you can consider how common a target’s name is in a given jurisdiction. The less common the name, the more confident you can be that two instances of it refer to the same individual. National voter rolls make great tools for assessing name frequency in a population, and some countries make them publicly available.
Using one or more of these approaches, internal teams can determine whether an entity flagged as potentially risky is a controlled entity or simply looks like one based on some of its identifiers. From there, cleared individual entities can be safely whitelisted to avoid future risk alerts and repeated due diligence.
Whitelisting multiple known entities
Proactively whitelisting multiple known entities at once, rather than reacting to alerts that are likely to occur in the future, can help mitigate alert fatigue.
For example, if you have a non-risky counterparty — John Doe — who might be confused with the notorious sanctioned entity John Doe, Jr., you would whitelist this entity. Now that you’ve disambiguated and whitelisted John Doe, you can search your internal data for vetted entities with similar names — such as Jon R. Doe, John Doen, or Jonathan Doe — and proactively whitelist those as well to prevent them from triggering unwarranted alerts in the future.
Whitelisting third-party entity lists
If you have access to a third-party list of non-risky entities that might be mistaken for a sanctioned entity, whitelist these to preempt a false flag in the event they do engage with your organization. This technique is more proactive than many companies require, but larger enterprises, particularly those that need the ability to screen third parties quickly and at a high velocity, are using it to their competitive advantage. Speedy screening can be a differentiating factor for financial institutions, for example.
Building on the John Doe example above, you might use your third-party data provider to develop a list of non-risky entities with names similar to John Doe, Jr. and whitelist these to ensure they do not create unnecessary work for your due diligence team in a future encounter.
Continuous monitoring of whitelisted entities
Whitelists, like blacklists, should be continuously monitored to ensure changes in risk status are accounted for. A safe entity today could be included on a watchlist tomorrow or could be indicated by a narrative-style regulation based on recent behavior, corporate relationships, or trade activity. All third parties should be monitored, regardless of risk status. Automated screening solutions can assist teams by displaying alerts in the event a whitelisted entity is added to a watchlist or is determined to be a risk.
Whitelisting with Sayari
To effectively whitelist, companies require both a depth and breadth of well-resolved entity data. Sayari provides comprehensive profiles and network context not just for watchlisted entities but for all 2.9 billion entities in its model.
“Prior to using Sayari,” says Rhoades, “I was limited in ways to differentiate restricted parties, and it was challenging to ensure I didn’t stop transactions to valid third parties. Sayari facilitates whitelisting by gathering, resolving, and visualizing data across a wide breadth of entities.”

“Sayari makes it much easier to whitelist. Prior to using Sayari, I was limited in ways to differentiate restricted parties, and it was challenging to ensure I didn’t stop transactions to valid third parties. Sayari facilitates whitelisting by gathering, resolving, and visualizing data across a wide breadth of entities.”
Sayari solutions deliver several capabilities to enable a confident whitelisting program:
- Sophisticated entity resolution minimizes false positives
Confident whitelisting starts with trustworthy entity resolution. Sayari’s proprietary entity resolution process mitigates false positives by allowing for two endpoints: identity resolution and possibly same as (PSA) resolution. Identity resolution collects entity references that confidently refer to the same real-world entity and aggregates these references into entities. Generally, these hard resolutions will be generated through a strong/unique identifier match (such as tax ID) or a combination of weak identifiers (such as name and address or name and date of birth).
PSA resolution, by contrast, collects entities into groups that likely refer to the same real-world entity. This conservative approach to entity resolution mitigates false positives by erring on the side of under-resolution. PSA groups, which can be curated on an organization-by-organization basis, leave room for analysts to confirm or deny resolutions based on their proprietary data.
Sayari strives for zero tolerance for false positives and avoids over-resolution to help prevent inaccurate whitelisting decisions.
- Comprehensive entity profiles supplement watchlist data
Detail-rich entity profiles are equally critical in enabling confident whitelisting. For each entity, Sayari provides attributes such as address, date of birth, and business purpose; financials; trade data; risk factors; and adverse media mentions. It also links that entity to related parties, shipments, and property where applicable, citing authoritative sources in all cases.
Watchlists tend to be sparse in detail, making entity disambiguation challenging. Let’s imagine a company named Beijing Androtech is flagged for a fuzzy match with Beijing Ander Tech, a watchlisted Military End User (MEU). BIS’s Entity List provides only Ander Tech’s name and address. This means that even if we have ample information about Androtech — including unique identifiers and a different Beijing address — we cannot confidently prove that Androtech isn’t in some way related to Andertech.

When we combine the MEU list data with public records available through Sayari, we can confidently disambiguate using a unique ID and the original Chinese names.
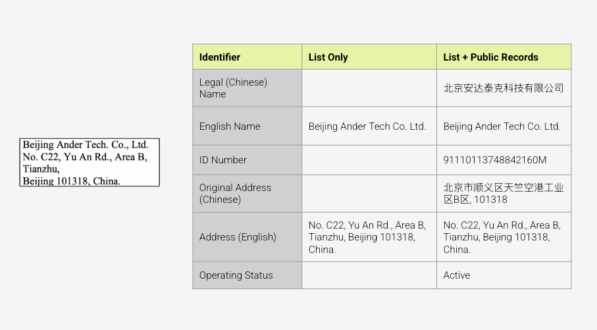
“Sayari is useful because it provides unique identifiers for even low-profile individuals,” says a senior researcher at a Geneva-based investigations company, “which means we can confidently say, ‘No, these people have the same name, but they’re different.’ And that sounds kind of basic, but if you get it wrong, then everything’s crumbled.”
- Networked data enables narrative risk assessment
Today, compliance teams must probe corporate ownership and control to identify the potential for end user risk. Additional information in public records, such as shareholders and subsidiaries, further contribute to confident decision making and whitelisting. For example, examining upstream and downstream corporate relationships to determine whether a counterparty has any direct or indirect ties to known high-risk end users can be an effective way to mitigate potential diversion of covered goods to restricted parties.
With Sayari’s network analysis and visualization capabilities, third-party risk management teams don’t have to consider an entity in isolation but, rather, can base their assessments on a complete picture of linked individuals, companies, shipments, and assets. Sayari automatically connects the dots across disparate data sources, which can be particularly useful when used to map ownership and control relationships. Otherwise hidden relationships are automatically illuminated, enriching or even transforming the analyst’s understanding of the subject. Sayari’s historical records help compliance teams assess entities’ past affiliations and behaviors in spite of any potential coverup attempts.
Going back to the example above, Sayari’s networked data would ensure that Ander Tech is flagged not just for its presence on the BIS Military End User (MEU) list, but also for narrative risks like having Xinjiang-based entities in its supplier network. Such comprehensive risk flagging ensures thorough screening in advance of whitelisting.
- Expansive dataset helps ensure target discovery
Sayari data comprises 8+ billion records covering more than 700 million companies and over 725 million individuals across 250+ jurisdictions worldwide. Even though Sayari’s risk indicators go beyond watchlists to include high-risk narrative typologies, fewer than 2% of the entities in Sayari’s dataset are flagged for risk, underscoring the importance of network context.
By delivering data on as wide a range of entities as possible, Sayari increases the chance that compliance teams will be able to positively match a flagged party (such as Androtech above) with a corresponding profile in Sayari. Establishing such a match enables further due diligence on that entity and ensures the compliance team will have evidentiary support for their risk determination.
Conclusion
As regulations grow more complex, third-party risk management teams are looking to introduce efficiencies and minimize overcompliance wherever possible. Whitelisting is essential for adapting to narrative-style trade restrictions and the problems of scale they introduce. Sayari, with its vast data model and detailed entity profiles, is a key enabler in the whitelisting process, as it helps teams confidently assert an absence of risk and minimize operational disruptions resulting from due diligence efforts.